Robotics
Multiple AI Models Help Robots Execute Complex Plans
A multimodal system uses models trained on language, vision and action data to help robots develop and execute plans for household, construction and manufacturing tasks.
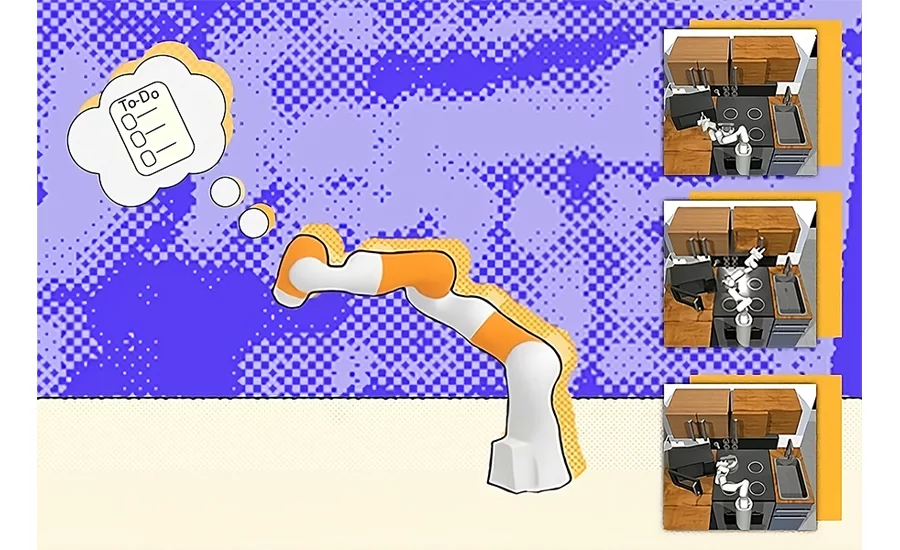
CAMBRIDGE, MA—Your daily to-do list is likely pretty straightforward: wash the dishes, buy groceries, and other minutiae. It’s unlikely you wrote out “pick up the first dirty dish,” or “wash that plate with a sponge,” because each of these miniature steps within the chore feels intuitive. While we can routinely complete each step without much thought, a robot requires a complex plan that involves more detailed outlines.
MIT’s Improbable AI Lab, a group within the Computer Science and Artificial Intelligence Laboratory (CSAIL), has offered these machines a helping hand with a new multimodal framework: Compositional Foundation Models for Hierarchical Planning (HiP), which develops detailed, feasible plans with the expertise of three different foundation models. Like OpenAI’s GPT-4, the foundation model that ChatGPT and Bing Chat were built upon, these foundation models are trained on massive quantities of data for applications like generating images, translating text, and robotics.
Unlike RT2 and other multimodal models that are trained on paired vision, language, and action data, HiP uses three different foundation models each trained on different data modalities. Each foundation model captures a different part of the decision-making process and then works together when it’s time to make decisions. HiP removes the need for access to paired vision, language, and action data, which is difficult to obtain. HiP also makes the reasoning process more transparent.
What’s considered a daily chore for a human can be a robot’s “long-horizon goal”—an overarching objective that involves completing many smaller steps first—requiring sufficient data to plan, understand, and execute objectives. While computer vision researchers have attempted to build monolithic foundation models for this problem, pairing language, visual and action data is expensive. Instead, HiP represents a different, multimodal recipe: a trio that cheaply incorporates linguistic, physical, and environmental intelligence into a robot.
“Foundation models do not have to be monolithic,” says NVIDIA AI researcher Jim Fan, who was not involved in the paper. “This work decomposes the complex task of embodied agent planning into three constituent models: a language reasoner, a visual world model, and an action planner. It makes a difficult decision-making problem more tractable and transparent.”
The team believes that their system could help these machines accomplish household chores, such as putting away a book or placing a bowl in the dishwasher. Additionally, HiP could assist with multistep construction and manufacturing tasks, like stacking and placing different materials in specific sequences.
The CSAIL team tested HiP’s acuity on three manipulation tasks, outperforming comparable frameworks. The system reasoned by developing intelligent plans that adapt to new information.
Looking for quick answers on assembly and manufacturing topics? Try Ask ASM, our new smart AI search tool. Ask ASM
First, the researchers requested that it stack different-colored blocks on each other and then place others nearby. The catch: Some of the correct colors weren’t present, so the robot had to place white blocks in a color bowl to paint them. HiP often adjusted to these changes accurately, especially compared to state-of-the-art task planning systems like Transformer BC and Action Diffuser, by adjusting its plans to stack and place each square as needed.
Another test: arranging objects such as candy and a hammer in a brown box while ignoring other items. Some of the objects it needed to move were dirty, so HiP adjusted its plans to place them in a cleaning box, and then into the brown container. In a third demonstration, the bot was able to ignore unnecessary objects to complete kitchen sub-goals such as opening a microwave, clearing a kettle out of the way, and turning on a light. Some of the prompted steps had already been completed, so the robot adapted by skipping those directions.
For more information on the study, click here.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!






